大晦日も淡々と自宅PoCをし、淡々と記事を書く。Terraform loop処理シリーズ、今回はEC2インスタンスに対するCloudWatch Alarmの作成をやってみる。
最初は定数バージョンのサンプルから。EventBridgeでアラームを検知する想定のためalarm_actionsは設定しない。
(補足)SNSと直接連携する場合は以下のように記述する。
alarm_actions = [aws_sns_topic.sns.arn]
################################################
# CloudWatch metric alarm
# 定数版
################################################
resource "aws_cloudwatch_metric_alarm" "alarm_001" {
alarm_name = "ec2-alarm-cpu-001"
comparison_operator = "GreaterThanThreshold"
evaluation_periods = "1"
metric_name = "CPUUtilization"
namespace = "AWS/EC2"
period = "60"
statistic = "Average"
threshold = "80"
alarm_description = "CPU Usage Check Alarm"
datapoints_to_alarm = "1"
treat_missing_data = "missing"
dimensions = {
InstanceId = "i-xxxxxxxxxxxxxxxxx"
}
}
上記はインスタンスi-xxxxxxxxxxxxxxxxxに対するCPU使用率監視のアラームを作成する。しかし実際にはひとつのインスタンスに対してメモリ、ディスク、複数のプロセス監視等を行うだろう。(あーEC2面倒くせぇ…)それらを繰り返し記述するのはありえないのでloopにする。
ちなみにここではTerraformで作成していないインスタンスを指定したのでインスタンスIDを直接指定しているが、インスタンスもTerraformで作成する場合は以下のように記述する。
dimensions = {
InstanceId = aws_instance.instance_001.id
}
以下がloopバージョン。インスタンスが複数ある場合、loopの固まりをその分追加で作成し、aws_instance.instance_002.id, aws_instance.instance_003.id …など指定すればよいかと。EC2インスタンス側もloopで作成する場合はまた参照方法が異なってくるが、EC2はlookupで参照するのは不可能と思われる。他のアラーム用パラメータとEC2のloopの順番は一致しないはずだから。(上手く言い表せない)
metric_alarm.tf
################################################
# CloudWatch metric alarm
# loop版
################################################
resource "aws_cloudwatch_metric_alarm" "alarm_001" {
for_each = var.ec2_alarm001_param_list
alarm_name = lookup(each.value, "alarm_name")
comparison_operator = lookup(each.value, "comparison_operator")
evaluation_periods = "1"
metric_name = lookup(each.value, "metric_name")
namespace = lookup(each.value, "namespace")
period = lookup(each.value, "period")
statistic = lookup(each.value, "statistic")
threshold = lookup(each.value, "threshold")
alarm_description = lookup(each.value, "alarm_description")
datapoints_to_alarm = "1"
treat_missing_data = lookup(each.value, "treat_missing_data")
dimensions = {
InstanceId = "i-xxxxxxxxxxxxxxxxx"
}
}
以下は参照する変数リストとなる。
metric_alarm.auto.tfvars
###########################################
# CloudWatch alarm vars
###########################################
ec2_alarm001_param_list = {
param1 = {
alarm_name = "ec2-alarm-system-001"
comparison_operator = "GreaterThanOrEqualToThreshold"
metric_name = "StatusCheckFailed_System"
namespace = "AWS/EC2"
period = "300"
statistic = "Maximum"
threshold = "1"
alarm_description = "Node Status Monitoring"
treat_missing_data = "missing"
}
param2 = {
alarm_name = "ec2-alarm-status-001"
comparison_operator = "GreaterThanOrEqualToThreshold"
metric_name = "StatusCheckFailed_Instance"
namespace = "AWS/EC2"
period = "300"
statistic = "Maximum"
threshold = "1"
alarm_description = "Node Status Monitoring"
treat_missing_data = "missing"
}
param3 = {
alarm_name = "ec2-alarm-cpu-001"
comparison_operator = "GreaterThanThreshold"
metric_name = "CPUUtilization"
namespace = "AWS/EC2"
period = "60"
statistic = "Average"
threshold = "80"
alarm_description = "CPU Usage Monitoring"
treat_missing_data = "missing"
}
param4 = {
alarm_name = "ec2-alarm-process-001"
comparison_operator = "LessThanThreshold"
metric_name = "procstat_lookup_pid_count"
namespace = "Prosess"
period = "60"
statistic = "Average"
threshold = "1"
alarm_description = "Process Monitoring"
treat_missing_data = "missing"
}
}
こんなやっつけコードだがあっさり期待値になった。
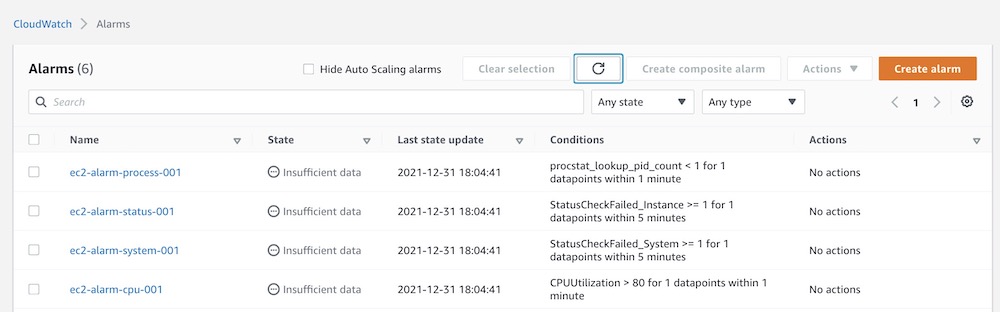
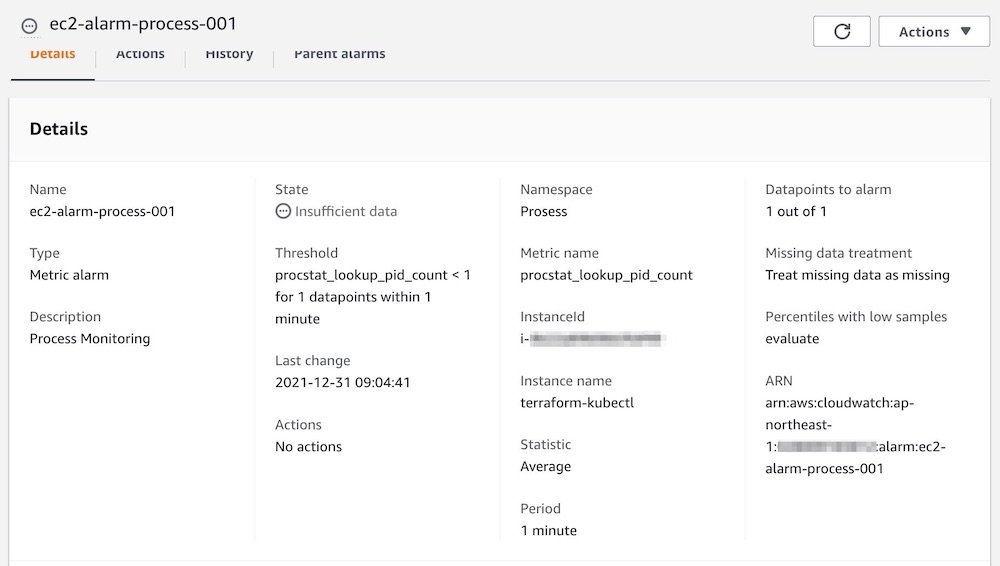
ちなみにこれはloop回数が4つ分だけだから手動で書いたが、実際にはもっと多くの監視項目が並ぶ。過去記事に書いたように変数リストを自動生成する仕組みを作った方がよい。
ということでこれまでTerraformのloop処理方式をいくつか探ってきたが、どのような構成にすべきかはそれなりに頭を捻る必要がある。構成というのは、全体的な範囲と、リソース毎の構成。tfコード本体と変数リストの組み合わせとか。loop処理にすべきかどうかはリソースの数にもよる。また、loopか否かによって参照するリソース側の記述も変わってくる。回答はひとつではないのである。
まぁ頭を捻る場面があるからこそ、面白いとも言えるけど。
